之前介绍的apriori算法中因为存在许多的缺陷,例如进行大量的全表扫描和计算量巨大的自然连接,所以现在几乎已经不再使用
在mahout的算法库中使用的是PFP算法,该算法是FPGrowth算法的分布式运行方式,其内部的算法结构和FPGrowth算法相差并不是十分巨大
所以这里首先介绍在单机内存中运行的FPGrowth算法
还是使用apriori算法的购物车数据作为例子,如下图所示:
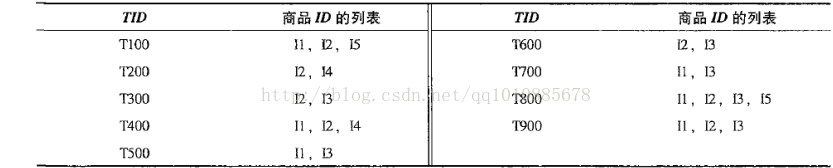
TID为购物车项的编号,i1-i5为商品的编号
FPGrowth算法的基本思想是,首先扫描整个购物车数据表,计算每个商品的支持度,并从大到小从上往下排序,得到如下表所示
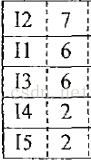
从底部最小支持度开始,逐一构建FP树
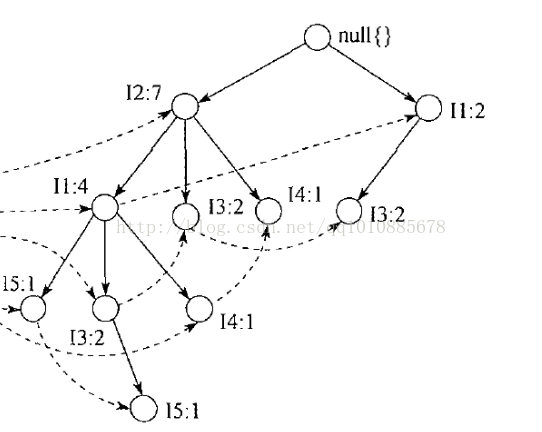
构建过程如下图:

最终构建出的FP树如下图
将这个FP树和支持度表关联起来如下图:
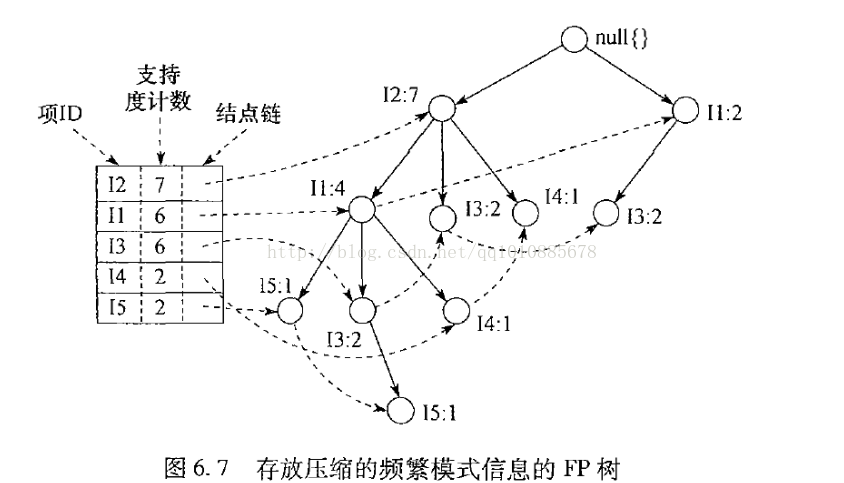
支持度表中的每一项都有一个存放指向FP树中对应节点的指针,例如第一行指向i2:7;第二行指向i1:4,因为i1节点还出现在FP树中的其他位置,所谓i1:4节点中还存放着指向i1:2节点的指针
通过少数的全表扫描构建好的FP树将购物车没有规律的数据变成了一个有迹可循的树形结构,并且省去了进行巨大的自然连接的运算
通过FP树挖掘出关联规则:
通过上图的FP树,我们可以根据每个商品得到该商品对应的条件模式基,条件FP树和产生的频繁模式
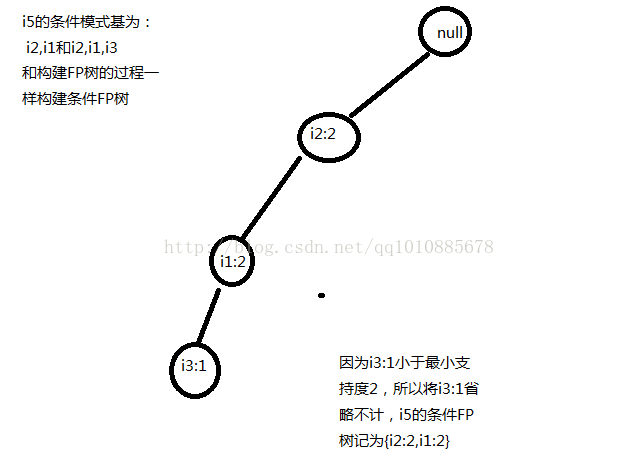
例如i5
在FP树中可以看到,从根节点到i5:1的路径有两条:
i2:7-->i1:4-->i5:1
i2:7-->i14-->i3:2-->i5:1
i2:7-->i1:4和i2:7-->i14-->i3:2就是i5的条件模式基,因为最终到达的节点肯定是i5,所以将i5省略
记为{i2,i1:1}{i2,i1,i3:1},为什么每个条件模式基的计数为1呢?虽然i2和i1的计数都很大,但是由于i5的计数为1,最终到达i5的重复次数也只能为1。所以条件模式基的计数是根据路径中节点的最小计数来决定的
根据条件模式基,我们可以得到该商品的条件FP树,例如i5:
根据条件FP树,我们可以进行全排列组合,得到挖掘出来的频繁模式(这里要将商品本身,如i5也算进去,每个商品挖掘出来的频繁模式必然包括这商品本身)
根据FP树得到的全表如下:

至此,FPGrowth算法输出的结果就是产生的频繁模式,FPGrowth算法使用的是分而治之的方式,将一颗可能十分巨大的树形结构通过构构建条件FP子树的方式分别处理
但是在商品数据十分巨大的情况下,FPGrowth算法所构建的FP树可能会大到计算机内存都无法加载,这时就要使用分布式的FPGrowth,PFP算法来进行计算
本文参考书:《数据挖掘概念与技术》